ApplyingML
Assorted Advice on Applying Machine Learning
The metagame is the game about/beyond the game, where you use external knowledge or factors to your advantage. For example, if you were playing rock-paper-scissors with a random stranger, knowing that males tend to throw rock and females tend to throw scissors tilts the game in your favor. For StarCraft, studying your opponent’s past gameplay for preferred build and play styles helps with preparing counterstrategy.
Or for the Massachusetts State Lottery, exploiting the rules allowed a syndicate to profit $700,000 in one week. Under the lottery (Cash WinFall) rules, players can win by matching 2, 3, 4, 5, or 6 of the six drawn numbers. And when the jackpot hits $2 million and no one wins it, the prize money “rolls down” to the smaller prizes (i.e., matching 2 - 5 of six drawn numbers). When this happens, picking 5 out of 6 numbers can lead to prize money 10x higher than the $4,000 in a regular week.
For six years, three syndicates milked Cash WinFall on “roll down weeks”. They bought a large number of tickets (312,000 by one syndicate leader’s account) and shifted the statistics in their favor, letting them win more than they lose. In a ballsy move, one syndicate from MIT bought 700,000 tickets—in a single week—to “push” the jackpot over $2 million earlier than expected—they made off with nearly the entire jackpot and pocketed $700,000 in profit.
How does this relate to machine learning? As an applied scientist, machine learning is the game, applying it in industry is the metagame. When I first started, I found a large gap between knowing machine learning (“here’s how a decision tree splits”) and applying it at work (“the decision tree ranker we shipped increased CTR and conversion by x%”).
While I don’t claim to be good at the game, let alone the metagame, here’s some tips on applying ML at work. Also see Vicki Boykis’ great post on the ghosts in the data.
Start from the problem (not the tech)
Choosing the right problem is half the battle won. Don’t solve problems that don’t matter to customers or the business, no matter how exciting the tech is. What matters to the business? Usually, it’s increased revenue or reduced cost, or capabilities that allow the business to solve other problems.
Identifying the right problem sometimes involves peeling the onion. In a previous role, someone from the logistics team had this request: “Could we boost the rank of products that are Fulfilled By Lazada (FBL)?” The request made business sense—I thought they wanted to improve the rank of FBL products to incentivize merchants to use FBL. Nonetheless, I asked, “Why?”
“Because FBL products are delivered faster.” Now it's clearer how this benefits customers; they get products faster! Nonetheless, I asked “Why?” again.
“Because when it’s delivered faster, we get fewer complaints about late deliveries.” Ah, now the root problem emerges. But late deliveries wasn’t a ranking problem—it was a delivery forecasting (and logistics) problem. To solve this problem, we should reduce the occurrence of underestimations in our delivery forecasting algorithm.
How we frame the problem is important too. To identify fraud we can either flag fraudulent transactions or greenlight safe transactions. To detect abuse on social networks, we can frame it as a supervised or unsupervised problem. As an unsupervised problem, we can adopt outlier detection (e.g., isolation forests) or network analysis (e.g., graph clustering). As a supervised problem, we’ll need to focus on collecting labelled data and having human-in-the-loop. Having the right frame often leads to outsized returns.
More system & data design, less model design
I've often found the overall system design to matter more than model architecture (most people refer to figure 1 in this tired paper). Also, model performance depends less on the model than the data we feed the model. Beyond data quality and quantity, how we design training data to teach our models makes the biggest difference.
When designing systems, less is more. With three key components (e.g., Spark, SageMaker, Airflow) and a team of three people, each person can take ownership of one component and gain in-depth knowledge of it. They even have bandwidth to shadow each other. With six components (e.g., adding Kafka, Redis, Lambda), it becomes harder for each person to learn and operate what they’re tasked with, and you certainly won’t have redundancy. Also, simple designs ship faster and are easier to maintain.
Monzo Bank’s feature store is a great example. They had a problem of serving features from their analytics store in production and designed the simplest solution to solve it—they periodically dumped features from their analytics store (BigQuery) into their production feature store (Cassandra). No need for real-time feature processing. Anything more would have been excess ops burden that would slow them down in the long run.
I didn’t want the feature store to become a replacement for things that already existed, or a behemoth that is owned by my (small) team. Instead, I learned about what we needed by looking for patterns in the machine learning models that we were shipping. — Neal Lathia, Monzo Bank
How we design training data can also make a difference. In natural language processing (NLP), Word2Vec and self-attention have led to breakthroughs on many NLP tasks. To benefit from this, companies have found innovative ways to shape user behavior data into sequences and fit the NLP paradigm. This has enhanced our ability to model entities (e.g., items, customers, queries) via embeddings. Plus, it’s all self-supervised!
A key part of training data design is creating negative samples—sometimes, it’s more an art than a science. For their search model, Facebook found that using impressed-but-not-clicked as negative samples led to 55% less recall (relative to using random samples). In contrast, Amazon found that using non-click impressions and accounting for it in their loss function led to better results. JD found that using a 1:1 ratio of random negatives and batch negatives led to optimal results. Clearly, there's no one size fits all approach.
When designing models, multiple modular models usually work better than an all-in-one model. When all-in-one models fail, they fail badly and are nearly impossible to debug. It’s easier to have a few smaller models with distinct objectives and implementation. For example, most industry recommenders have a two-stage approach: Retrieval which is fast but coarse and focuses on recall, and ranking which is slower but more precise and focuses on precision. This also allows multiple teams to work independently and in parallel.
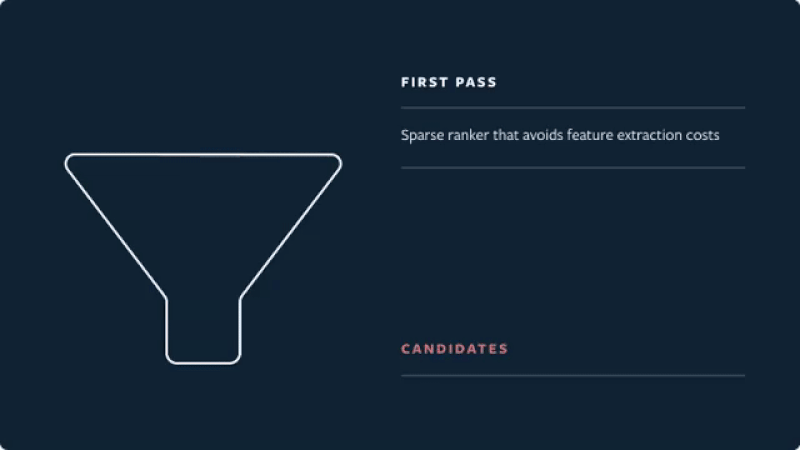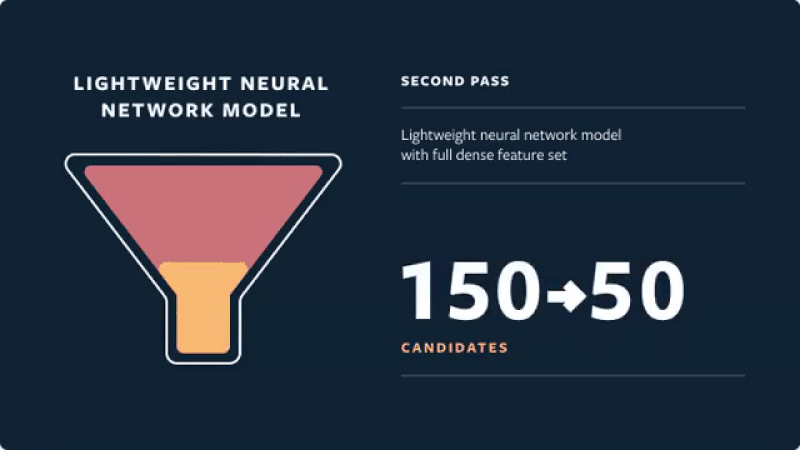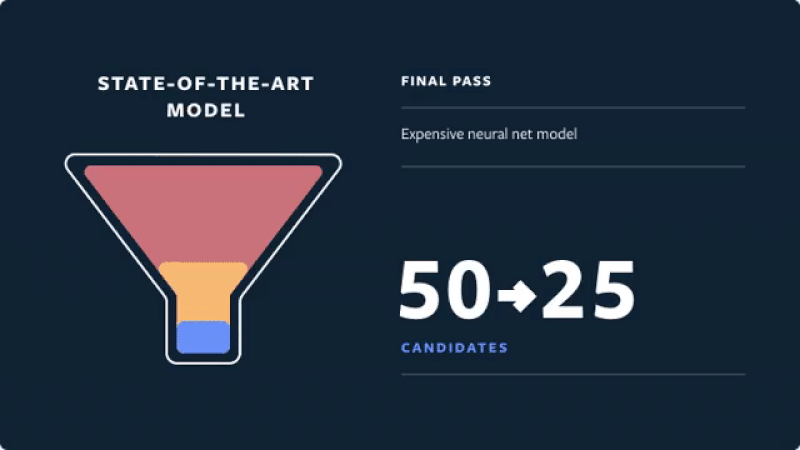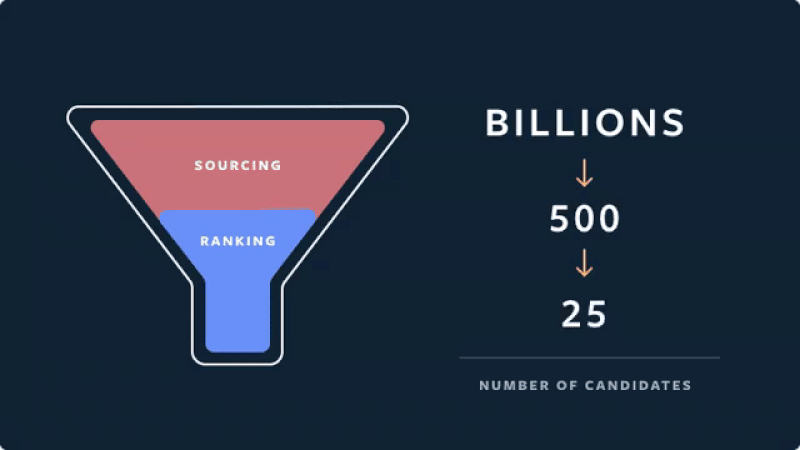
Be clear about your objectives and measurements
Don’t confuse a lower model loss with a better product. How often has a model excelled in offline validation but flopped in an A/B test? (The reverse keeps me up at night—how often have I prematurely killed good models because they didn’t have the best result offline?) AFAIK, having an experimentation pipeline that lets you quickly iterate through A/B tests is the best way to assess models.
If I had an hour to build a model, I’d spend 55 minutes building a fast and unambiguous evaluation procedure and 5 minutes trying out models. — Sean J. Taylor (@seanjtaylor)
Sometimes, your objectives might be clear and conflicting and you have to mediate between stakeholders.
In my case, we found two objectives for which we wanted to optimize: conversion and revenue. However surprisingly, when I said I could jointly optimize both and potentially find a nice optimum between the two, I got pushback b/c some parities wanted to favor conversion over revenue or vice versa! — Alex Egg
Optimizing for conversion might involve reducing the price point of products in recommendations and search results; optimizing for revenue might do the opposite. Groceries are cheaper and tend to convert more often (e.g., weekly) relative to mobile phones (e.g., once every 2 - 3 years). Furthermore, different categories might have different goals—electronics might focus on revenue while FMCG might focus on stickiness (e.g., weekly average users) and recurring conversion.
Be clear about the measurement period—is it short-term (e.g., session-based), long-term (e.g., 1-year estimate), or something in between? (We can estimate long-term changes via approaches such as double machine learning.) Certain personas, such as new or expecting parents, are a boon for long-term metrics. Get them to start using your diapers and milk formula and they’ll likely be your customer for the next few years—babies are finicky about their milk and using different diapers can cause a rash. Similarly, groceries tend to be bought weekly and are great for stickiness and customer lifetime value.
Keep learning, yet respect what came before
The game of machine learning evolves quickly. In NLP, new models are released yearly: Word2Vec (2013), GloVe, GRU (2014), FastText (2016), Transformer, GPT (2017), ELMo, BERT (2018), T5 (2019), etc. Reading papers keep us up to date so we can adopt new techniques to build better models. It also applies to system design. Planning to build a feature store? Learn how others have implemented them, what their key needs were, and the various patterns, before designing your own.
Nonetheless, remember that we’re not building in a vacuum. Unless we’re working in a brand new startup, we’ll have existing systems to integrate or work around—it’s almost never an option to sweep it all away and start from scratch with the latest and greatest. Respect the existing systems that have been chugging along and invest the effort to learn why and how they solve existing problems.
You need to speak and build trust for your work
Your work can’t speak for itself—you need to communicate its value to a non-technical audience. I’ve found internal newsletters helpful for increasing awareness about data and our team. We would share the results of our collaboration with various stakeholders and after each newsletter, stakeholders would reach out: “You know that thing you did for them? Can you do it for us?” Open demos also work well.
The human connection is also important for building trust. With trust, minor imperfections won’t matter; without trust, perfect work and analysis won’t get anywhere. Treat each stakeholder as a customer and friend and sincerely want for them to succeed. Learn how they work and what their goals are before leaping into a solution.
Still thinking about some advice from my last 1:1 from my boss:
"It's not the best idea or the best analysis that wins, it's the best relationship." — Erika Pullum (Swartz) she/hers (@eswartz)
Expect to fail, but keep calm and experiment a lot
I've many failed offline experiments and A/B tests but each non-positive result is still hard to swallow. It helps to view each loss as a learning opportunity, just like a game. Each is a puzzle to figure out and learn something valuable from, though there might be some that just can’t be cracked. (I still need to remind myself of this regularly.)
You won't be able to solve every problem thrown at you, no matter how hard you try, and that's okay. You work your best towards it, and be content with what you managed to achieve. — Zach Mueller (@TheZachMueller)
It also helps to always have an experiment or two ready to go. This helps me look towards the future and focus on the opportunities that lie ahead.
“Life is like riding a bicycle. To keep your balance, you must keep moving.” - Albert Einstein
Keep your conscience clean
Finally, if you’re in this for the long haul, keep your conscience clean. What you build has the ability to affect people, for better or for worse. I had previously built a model that could, given a person’s historical health events, predict chronic diseases (e.g., cardiovascular diseases, diabetes) 2 - 3 years in advance. We wanted to work with insurers on preventive care—they would save money on insurance payouts and we would improve people’s health.
One insurer had a surprising—and scary—idea. They asked if we could predict who would not develop chronic disease so they could sell them more insurance. From a business standpoint, it’s easier to make more money today than spend money (on preventive care) to save money tomorrow. But how long till it’s used to discriminate against the people who are most in need of health insurance? I wouldn’t have been able to sleep knowing that I had a part in it. Needless to say, I walked away.
Don't neglect the metagame
Machine learning is a fun game. Nonetheless, there’s a whole metagame around applying it at work and driving impact. I won’t cite statistics on how x% of companies still have difficulty deploying and reaping the benefits of ML, but the last I heard, it’s still dishearteningly high. I hope these tips help to increase the success rate.
Read more guides?
Want email updates on new content?
© Eugene Yan 2024 • About • Suggest edits.